
C#の文字列はUTF-16を使用しているので、UnicodeとUTF-16を中心とした話になります。
目次
要約
- Unicodeに関する前提知識
- Unicodeでは各国で使用する文字一覧を定義(符号化文字集合)しており、U+01234等のコードポイントで文字を識別する。
- Unicodeの文字をコンピュータで表現する方法(文字符号化方式)として、UTF-8, UTF-16, UTF-32等が決められている。
- C#の文字列はUTF-16を使用している。
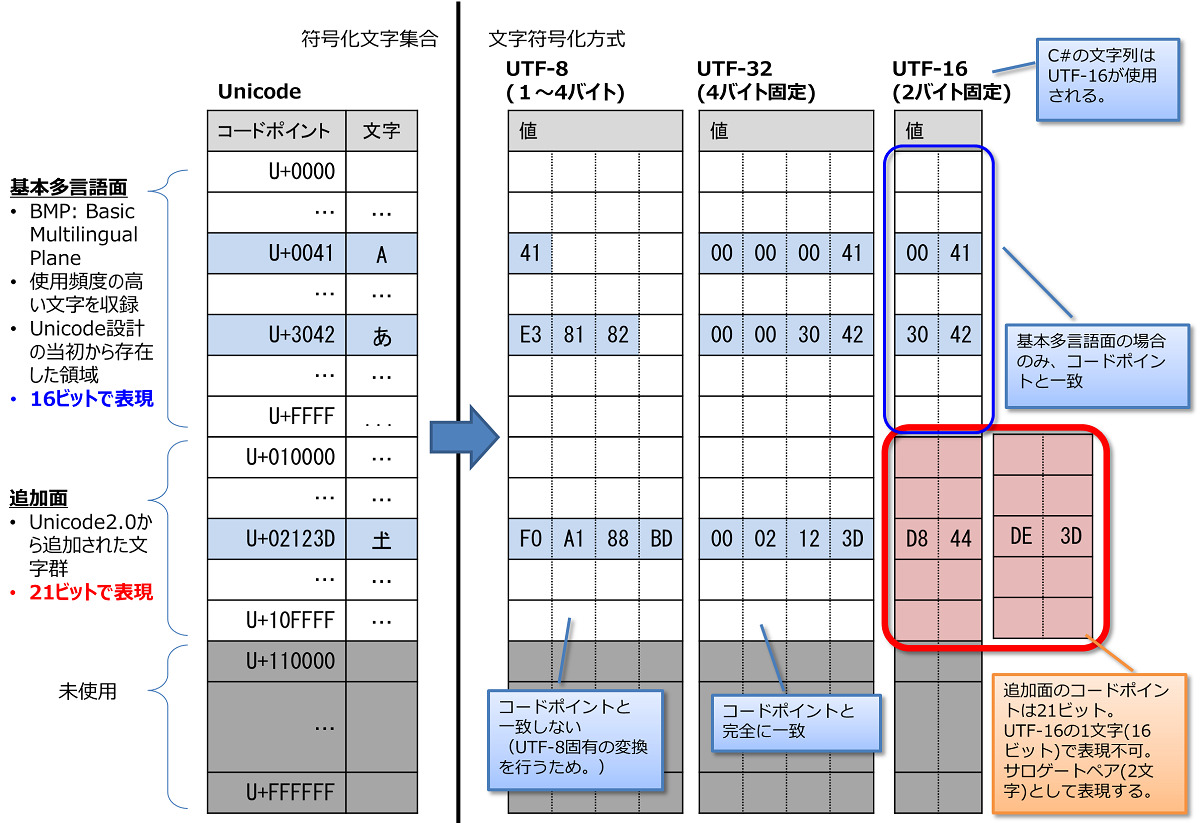
Unicodeの基本多言語面(BMP)のコードポイント値はUTF-16と一致する。
追加面(BMP以外)のコードポイント(U+010000~U+10FFFF)は1文字(16ビット)では表現できないので、2文字で1コードポイントを表現するサロゲートペアの仕組みを使用する。 - UTF-8, UTF-32では最大4バイト(32ビット)であり、Unicodeの全てのコードポイントを表現できるのでサロゲートペアは使用しない。(サロゲートペアはUTF-16のみで使用される。)
- UTF-32は全てのコードポイントと一致する。
- C#での変換方法の概要
- コードポイントとUTF-16/UTF-32がどこまで一致しているかの理解、UTF-16とサロゲートペアの関係の理解がポイントだと思います。
- コードポイントから文字列への変換は、Char.ConvertFromUtf32(int)を使用する。
- 文字列からコードポイントへの変換は、string型からchar型へ変換することで実現できる。char型はコードポイントを表現するため。ただし、サロゲートペアの場合は2文字で単一のコードポイントに変換するためのChar.ConvertToUtf32(char, char)を使用する。
- 文字列のUTF-8/UTF-16/UTF-32での値は、次のオンラインツールで確認できます。

詳細の説明
Unicodeの概要
Unicodeに関する最小限の知識を説明します。
- Unicodeは使用する文字の一覧を定義(符号化文字集合)したものです。
- Unicodeの文字は、符号位置(コードポイント)で識別され、「”U+”+16進数」という形式で表現されます。
(例:「あ」はコードポイント「U+3042」) - 各国共通の使用頻度の高い文字群を基本多言語面(BMP: Basic Multilingual Plane)として定義し、16ビットで表現できるように設計されました。(Unicode 1.0)
- Unicode1.0公表後、各国から大量の文字追加要求がありました。基本多言語面(16ビット)には収まらなくなったので、16ビット以上の新しい領域を追加することになりました。この追加された領域は、追加面(U+010000~U+10FFFF)と呼ばれ、21ビットで表現されます。(Unicode 2.0)
- 結果としてUnicodeで使用されるコードポイントの範囲は、U+0000~U+10FFFFの21ビット長になりました。
基本多言語面のコードポイントはU+xxxx(16進数4桁)、追加面のコードポイントはU+xxxxx(16進数5桁)で表現されます。分類 コードポイント範囲 長さ 表記例 基本多言語面 U+0000 ~ U+FFFF 16ビット U+3042 追加面 U+010000 ~ U+10FFFF 21ビット U+2123D
UTF-8/UTF-16/UTF-32の概要
- Unicodeの文字をコンピュータで表現する方法(文字符号化方式)として、UTF-8, UTF-16, UTF-32等が使用されます。これらは、データ量の削減やデータ処理のしやすさ等に基づいて使い分けられます。
文字のマッピング例 説明 「A」
(ASCII)「あ」
(日本語)「𡈽」
(サロゲートペア)コードポイント U+0041 U+3042 U+2123D Unicodeコードポイント UTF-8 41 E3 81 82 F0 A1 88 BD 1文字を1~4バイト(32ビット)で表現。 UTF-16 0041 3042 D844 DE3D 1文字を2バイト(16ビット)で表現。
サロゲートペアは2文字(4バイト)で表現。UTF-32 00000041 00003042 0002123D 1文字を4バイト(32ビット)で表現。 - UTF-8は1~4バイトの可変長(最大32ビット)で、基本多言語面・追加面の全てのコードポイントを表現できます。
基本的にUTF-8とコードポイントの値は一致しないため、独自に変換する必要があります。 - UTF-16は固定2バイト(16ビット)で、基本多言語面のコードポイント(16ビット)は表現できるのですが追加面のコードポイント(21ビット)は表現できません。追加面の文字に関しては、UTF-16の2文字(32ビット)で1文字(1コードポイント)を表現するサロゲートペアの仕組みを使用します。
基本多言語面のコードポイントと一致しますが、追加面はサロゲートペア用の特別な変換を行うのでコードポイントとは一致しません。
(サロゲートペアは、追加面を表現できないUTF-16のための特別な仕組みです。) - UTF-32は固定4バイトで32ビットの表現が可能で、基本多言語面・追加面の全てのコードポイントを表現でき、全てのコードポイントと一致します。
リンク
C#言語におけるUnicodeの取り扱い
- C#の文字列のエンコーディングにはUTF-16が使用されており、サロゲートペアの考慮が必要となります。サポートするUnicodeバージョンは.NET Core 3.1の場合は11.0.0となります。詳細はString型のリファレンスをご覧ください。
- ここでは扱いませんが、C#でファイル操作を行う場合の既定のファイルエンコーディングはUTF-8になっていますので、混乱しないように注意が必要です。詳細はリファレンスをご覧ください。
- 文字列宣言時、Unicodeエスケープシーケンスを使用してUTF-16かUTF-32で文字を宣言できます。UTF-16の場合はサロゲートペアの考慮が必要ですが、それ以外はUTF-16やUTF-32の値はコードポイントと一致するため、実質コードポイントで指定できます。
項目 定義方法 定義例 説明 Unicodeエスケープシーケンス
(UTF-16)\uHHHH \u00E7 16進数4桁で指定 Unicodeエスケープシーケンス
(UTF-32)\UHHHHHHHH \U0001F47D 16進数8桁で指定 - 追加面の文字を使用する場合は次のように宣言できます。
※例として、「𡈽」(U+2123D)を宣言する場合項目 定義方法 説明 Unicodeエスケープシーケンス
(UTF-16)\ud844\ude3d サロゲートペアの変換で算出した2文字を指定 Unicodeエスケープシーケンス
(UTF-32)\U0002123D コードポイントをそのまま指定 - Unicodeエスケープシーケンスで宣言した文字は、コンパイル時にUTF-16文字に変換されます。
そのため、実行時に動的に”\u00E7″等のUnicodeエスケープシーケンス文字列を作成しても、そのコードポイントが示す文字として認識されません。実行時に変換を行う場合は、後述のサンプルのように変換する必要があります。
コードポイントと文字列の変換サンプル
コードポイントと文字列で変換を行うサンプルを紹介します。
サンプルはVisual Studio 2019(C# + .NET Core 3.1)で動作確認しました。
完全なソースコードはこちらをご覧ください。
コードポイントを文字列に変換
引数で指定された複数のコードポイントを含む文字列を、C#の文字列に変換します。
例えば、引数として”U+0041U+3042U+2123D”が指定された場合、”Aあ𡈽”が返却されます。
public string GetStringFromCodePoints(string codepoints)
{
var hexes = Regex.Split(codepoints, "U\\+", RegexOptions.IgnoreCase);
var sb = new StringBuilder();
foreach (var hex in hexes)
{
if (string.IsNullOrEmpty(hex)) continue;
var codepoint = Convert.ToInt32(hex, 16);
var chstr = Char.ConvertFromUtf32(codepoint);
sb.Append(chstr);
}
return sb.ToString();
}- コードポイントを文字列に変換する場合は、Char.ConvertFromUtf32(int)を使用します。
- 引数はint型(32ビット)になっており、UTF-32の値=コードポイント値を指定して、C#の文字列(UTF-16)に変換できます。
- メソッド名がUtf32となっているので混乱するかもしれませんが、リファレンスを読むと「コードポイントをUTF-16文字列に変換する」とあるので期待する使用方法だと考えられます。
文字列をコードポイントに変換
引数で指定された各文字に対応するコードポイント文字列を生成します。
例えば、引数として”Aあ𡈽”が指定された場合、”U+0041U+3042U+2123D”が返却されます。
public string GetCodePointsFromString(string str)
{
var sb = new StringBuilder();
var chars = str.ToCharArray();
for (var i = 0; i < chars.Length; i++)
{
int codepoint;
if (Char.IsSurrogate(chars[i]))
{
// TODO: 2文字目有無やサロゲートペアかの検証が必要
codepoint = Char.ConvertToUtf32(chars[i], chars[i + 1]);
i++;
}
else
{
codepoint = (int)chars[i];
}
var codepointStr = "U+" + codepoint.ToString("X4"); // 4桁~5桁
sb.Append(codepointStr);
}
return sb.ToString();
}- C#の場合、char型はコードポイントを格納する想定になっています。
- そのため、stringのChars[int]やToCharArray()等でchar型に変換することでコードポイントに変換できます。
- サロゲートペアの文字の場合は2文字で1コードポイントになります。この変換を行うために、Char.ConvertToUtf32(char, char)を使用します。
リンク